
対話型AIサービスの脆弱性診断に対応

弊社は、対話型AIサービスに対する脆弱性診断の提供を開始しました。
大規模言語モデル (LLM) を用いた対話型AIの需要が増加しています。しかし、そのセキュリティリスクの評価は、一般的な脆弱性診断のプロセスでは困難です。弊社は、独自のハニーポットにより対話型AIへの最新の攻撃パターンを独自に収集・分析し、その診断手法を体系化しました。ECサイト上のチャットサービスから、アプリケーション開発者向けプラグインに至るまで、日本語環境対応・先端研究に基づく診断を提供します。
サービス詳細
対話型AIサービスとプロンプト
■ 対話型AI
対話型AIとは、ユーザーと自然な対話ができるように設計されたAIです。対話型AIは、テキストベースのチャットや音声ベースの音声アシスタントなどの形で提供されます。ユーザーが対話型AIとコミュニケーションを取ることで、対話型AIは質問への返答、情報の収集などを行います。対話型AIは一般的に、大規模言語モデルを基礎として構築されます。モデルは、対話の文脈を理解し、次の応答を生成するために利用されます。
■ 入力プロンプトと内部プロンプト
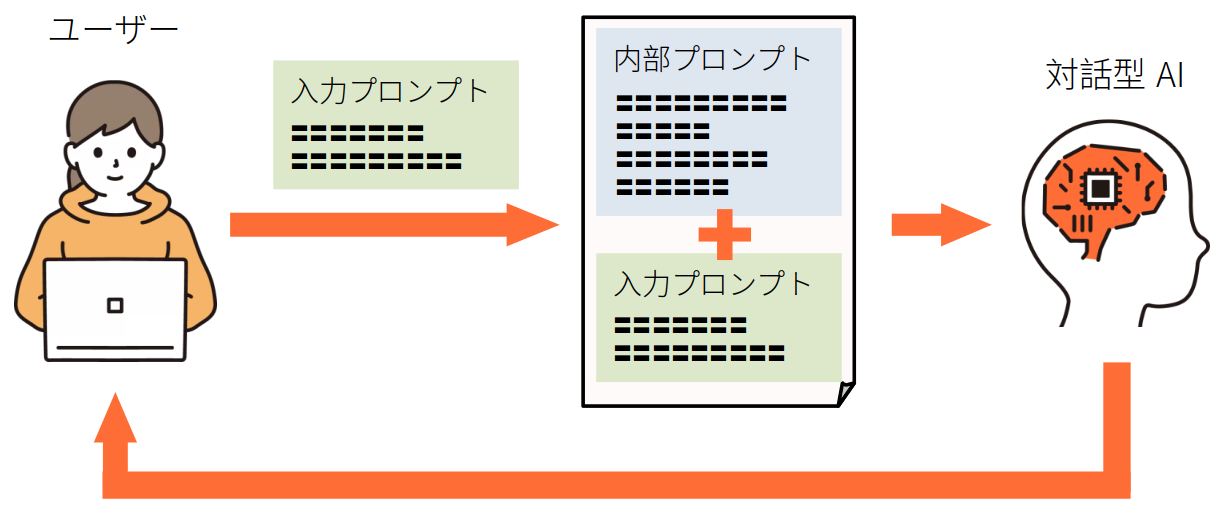
対話型AIを取り入れたサービスでは、ユーザーの入力に対してAIが応答を返すサイクルにより、相互に情報の交換が行われます。ユーザー対話型AIサービスに提供する具体的な質問や指示のテキストを、入力プロンプトと呼びます。入力プロンプトでは、どのような情報を求めているのかを明確に伝える必要があります。
一方で、あらかじめ内部に設定されたプロンプトのテンプレートを内部プロンプトと呼びます。内部プロンプトは、ユーザー入力の他にソフトウェア自体の振る舞いの方向性を決めます。ソフトウェアの出力形式の指定や、応答に利用する情報、倫理的な禁止事項などが設定されるのが一般的です。
■ 対話型AIサービスへの攻撃
対話型AIサービスへの攻撃は、攻撃者が特殊な入力プロンプトをソフトウェアへ送信し、その応答を入力プロンプトにフィードバックするサイクルを繰り返すことで実行されます。このサイクルを通じて生成された攻撃パター�ンを敵対的プロンプトと呼びます。敵対的プロンプトは、ソフトウェア内部の情報を詐取したり、不正な応答を引き出したりといった、通常禁止された動作を対話型AIサービスへ強要します。敵対的プロンプトへの対策として、入出力のフィルタ機構を導入しているサービスが見受けられますが、日々多様化する攻撃手法に対応することが求められています。
対話型AIサービスに対する診断メニュー
■ 対話型AIサービスのブラックボックス診断
弊社のAIエンジニアチームが、敵対的プロンプトを用いてサービスを診断します。頻出の攻撃パターンからサービスに特化したパターンまで、多角的な視点からサービスを診断可能です。
■ 対話型AIサービスのホワイトボックス診断
内部プロンプトの実装を考慮したソフトウェア全体への診断を行います。また、対話型AIサービスへのファイアウォールの実装など、周辺ソフトウェアを含めた診断にも対応します。
■ 対話型AIサービスを対象としたセキュリティコンサルティング
堅牢なプロンプト設計や、対話型AIの応答からの意図しない情報流出対策など、弊社研究者が対話型AIサービスのセキュリティ品質向上に関するノウハウを提供いたします。
弊社独自の診断データセット
弊社は、日本語環境に最適化された独自の敵対的プロンプトのデータセットを構築し、対話型AIに対する脆弱性診断サービスに取り入れています。この取り組みは、独自のLLMハニーポットの運用を通じた実際の攻撃事例の収集に下支えされています。
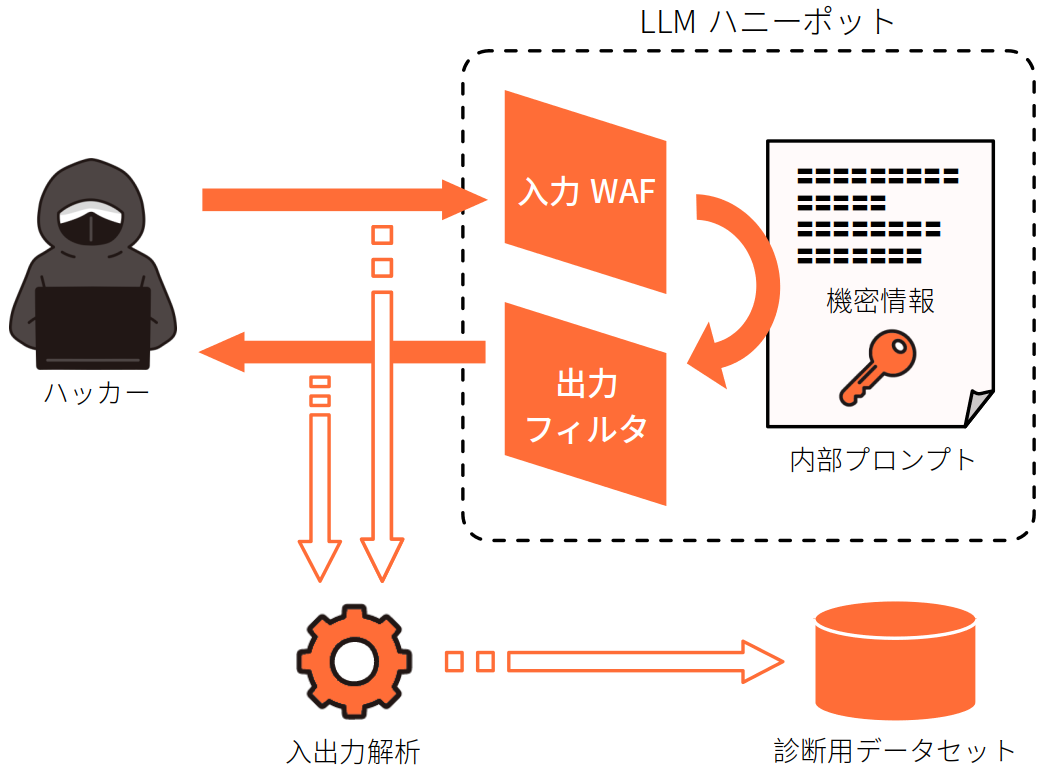
■ LLMハニーポットでの敵対的プ�ロンプト収集
ハニーポットとは、悪意のある攻撃を収集するために公開されているおとりサービスです。弊社は、対話型AIサービスを模擬したLLMハニーポットを独自に開発・運用しています。当該ハニーポットは、一般的な対話型AIサービスと同様に、機密情報の窃取 (Prompt Injection) を防止する入力ファイアウォールや、出力の汚染 (Jailbreak Prompt) を防止する出力フィルタを備えています。このハニーポットの特殊な点は、入力ファイアウォールや出力フィルタを複数備えていることで、どの攻撃パターンがどの対策を回避可能なのか詳細な分析を可能にしています。ハニーポットは全世界に公開され、日々ホワイトハッカーや悪意のある攻撃者からのプロンプトに晒されてます。これにより弊社は、入出力保護機構をバイパスする先端的な攻撃手法にキャッチアップしています。
弊社AIエンジニアチームは、日々ハニーポットを用いて収集した敵対的プロンプトを解析しています。そして、入出力保護機構を突破する新たな攻撃パターンとその原理を研究し、各言語環境に特化した診断用プロンプトのデータセットを開発しています。原時点で、日本語に特化したデータセットの開発に成功しており、本メニューの公開に至りました。
対話型AIサービスのリスクの例
対話型AIサービスのリスクには、機密情報の流出やレピュテーションの汚染などが挙げられます。
■ 内部プロンプトや機密情報の漏洩
対話型AIサービスの振る舞いを決める内部��プロンプトは、企業独自のデータから構成されます。内部プロンプトは時として機密情報を含む場合もあるため、保護すべき情報資産です。弊社では、内部プロンプトや機密情報の漏洩をねらった攻撃手法、Prompt Injectionを研究しています。具体的には、通常は出力フィルタにより検閲されてしまう出力を、フィルタを回避するように変換して出力するような敵対的プロンプトを与えます。Prompt Injectionは、対話型AIへの代表的な攻撃手法として知られており、弊社のハニーポットでも多数観測されています。
■ 応答でのサイトレピュテーション汚染
対話型AIサービスの内部プロンプトは、差別的な発言や事実と異なる情報の出力を規制しています。弊社では、この規制を回避する攻撃手法、Jailbreak Promptを研究しています。Jailbreak Promptを用いた出力を、意図的にクローラへ渡すことでサイトレピュテーションを汚染する攻撃も考案されています。
■ その他の脅威
対話型AIは必ずしも正しい答えを返すとは限りません。事実と異なる出力をHallucinationといい、これを悪用した攻撃も知られています。
対話型AIはアプリケーション開発者にとっても有用です。アプリケーション開発者が、対話型AIにアプリケーションのロジックやプログラムを書かせることも一般的になりつつあります。
しかし、Hallucinationにより、例えば実在しないパッケージを、プログラムが利用するパッケージ名としてコード内に組み込んでしまうことがあります。このとき、出力された実在しないパッケージと同名のパッケージを攻撃者が新たに登録する�ことで、対話型AIの出力を信頼したユーザーに悪意のあるパッケージを読み込ませ、任意のコマンドを実行させることが可能になります。
このような脅威は、対話型AIサービスへの入出力の監視では検出が難しいという特徴があります。
ソリューションの特徴
弊社の対話型AIサービス診断では、内部プロンプトや機密情報の漏洩リスク、応答によるレピュテーションの低下リスクを検証します。さらに、実際にレピュテーション汚染が行われているかどうかも調査可能です。
弊社は、一般的な対話型AIのみならず、日本語環境に特化した対話型AIに対応しています。また、対話型AIそれ自体だけでなく、対話型AIを組み込んだサービス全体の診断に対応しています。
■ 日本語環境特化・先端研究に基づく診断
弊社AIエンジニアチームが考案した日本語特化の診断項目により、流通している海外データセットでは発見が難しいマルチバイト等に起因する脆弱性を発見可能です。攻撃者に知られていない独自手法を診断に用いるため、将来的なリスクを未然に軽減可能です。
■ 対話型AIサービスのアーキテクチャ・実装まで踏み込んだ診断
対話型AIは、ECサイトのサポートチャット機能など、大規模サービスの一部機能として導入される形態が一般的です。弊社では、こうした対話型AIを囲む周辺Webアプリケーションの診断も可能です。併せて診断を実施することで、対話型AIサービスの出力結果が、周辺Webアプリケーションに損害を与えうるかの検証などが可能になります。
お問い合わせ
対話型AIサービスの脆弱性診断は以下ページよりお問�い合わせください。
お問い合わせページ